Cloud Defense Automation: Building Your Own Security Command Center
Part 1 - Security Scans and Data Aggregation
Our cloud resources have been growing steadily, and with that growth comes the need for tighter security. Recent industry data shows the following:
- 80% of organizations experience at least one cloud security incident each year. Source
- Nearly 70% of cloud security breaches stem from misconfigurations, which often slip through manual reviews and lead to critical exposures. Source
The bottom line is that without proper security management and investment in skilled staff, each new cloud resource added could increase operational and financial risk.
While we're still far from achieving a perfect security posture, this project aims to take a step in the right direction by implementing automated security scans across our multi-cloud environment. In this section, I'll discuss the bare bones of the system – where we'll run our scans, aggregate the data into a usable format for a dashboard (more on that later), and upload all output files to centralized storage. In an attempt to do this as cost-efficiently as possible, I decided to make use of always-free or low-cost infrastructure.
Here's how the system is designed:
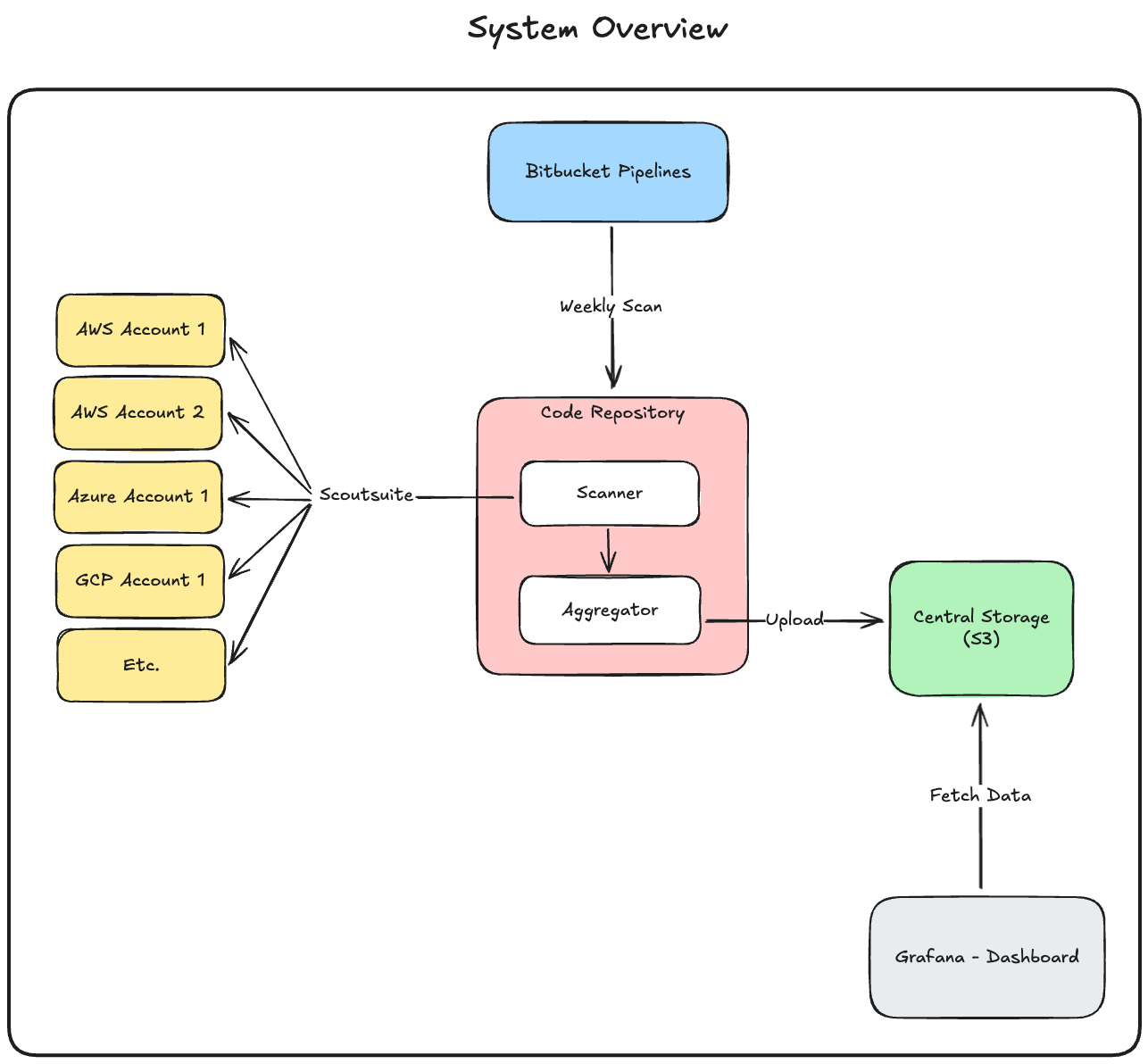
Scanner
Before we can scan an account, we need to set up a role or service account that our code can assume. The process for this varies significantly between each cloud provider, but it's important that we apply the principle of least privilege and only grant permissions that are absolutely necessary. I used the role definitions from ScoutSuite's documentation, which can be found here. Once a role or service account has been set up, cloud accounts can be configured through environment variables, giving us easy access to add or remove accounts when running our job from a CI/CD pipeline.
The scanning portion is relatively simple – we loop through the cloud accounts we have access to and use ScoutSuite to asynchronously scan each one and generate automatic reports for us. Here's a look at the core loop:
async def process_provider_projects(
cloud: CloudProvider,
projects: List[CloudAccount]
):
tasks: List[Coroutine[Any, Any, None]] = []
for proj in projects:
account = proj.account
enabled = proj.enabled
secret = fetch_project_secret(cloud, account)
if cloud == CloudProvider.AWS:
t = await run_aws_scan(account_id, secret, semaphore)
if cloud == CloudProvider.GCP:
t = await run_gcp_scan(account_id, secret, semaphore)
if cloud == CloudProvider.AZURE:
t = await run_azure_scan(account_id, secret, semaphore)
tasks.append(t)
await asyncio.gather(*tasks)
Once all the scans have finished, we can move on to the next step – data cleanup and aggregation.
Aggregator
The purpose of the aggregator is to combine and flatten data from all scans to make it easy to visualize later on our dashboard. Since we're currently only using ScoutSuite, this is fairly straightforward – we just need to parse the ScoutSuite scan results and extract metrics that help us understand our security posture across cloud services at a glance. I created a simple class to store the aggregated data and loop through each scan's results to add them to the final report. The core logic of the class looks like this:
class FinalReport:
"""
A final report to aggregate stats from data across all scans
"""
def __init__(self) -> None:
self.report_date = date.today().strftime("%m-%d-%Y")
self.aws = {
"acm": ServiceStats(),
"awslambda": ServiceStats(),
"cloudformation": ServiceStats(),
"cloudfront": ServiceStats(),
"cloudtrail": ServiceStats(),
"cloudwatch": ServiceStats(),
"codebuild": ServiceStats(),
"config": ServiceStats(),
"directconnect": ServiceStats(),
"dynamodb": ServiceStats(),
"ec2": ServiceStats(),
"efs": ServiceStats(),
"elasticache": ServiceStats(),
"elb": ServiceStats(),
"elbv2": ServiceStats(),
"emr": ServiceStats(),
"iam": ServiceStats(),
"kms": ServiceStats(),
"rds": ServiceStats(),
"redshift": ServiceStats(),
"route53": ServiceStats(),
"s3": ServiceStats(),
"secretsmanager": ServiceStats(),
"ses": ServiceStats(),
"sns": ServiceStats(),
"sqs": ServiceStats(),
"vpc": ServiceStats(),
"total": ServiceStats(),
}
self.azure = {
"aad": ServiceStats(),
"appservice": ServiceStats(),
"keyvault": ServiceStats(),
"loggingmonitoring": ServiceStats(),
"mysqldatabase": ServiceStats(),
"network": ServiceStats(),
"postgresqldatabase": ServiceStats(),
"rbac": ServiceStats(),
"securitycenter": ServiceStats(),
"sqldatabase": ServiceStats(),
"storageaccounts": ServiceStats(),
"virtualmachines": ServiceStats(),
"total": ServiceStats(),
}
self.gcp = {
"bigquery": ServiceStats(),
"cloudmemorystore": ServiceStats(),
"cloudsql": ServiceStats(),
"cloudstorage": ServiceStats(),
"computeengine": ServiceStats(),
"dns": ServiceStats(),
"functions": ServiceStats(),
"iam": ServiceStats(),
"kms": ServiceStats(),
"kubernetesengine": ServiceStats(),
"stackdriverlogging": ServiceStats(),
"stackdrivermonitoring": ServiceStats(),
"total": ServiceStats(),
}
self.total = ServiceStats()
def addSummary(self, cloud: CloudProvider, data: ScoutReport) -> None:
"""
Add a scoutsuite generated report to the final report
"""
summary = data.get("last_run", {}).get("summary", {})
if cloud == CloudProvider.AWS:
for key in self.aws.keys():
if key != "total":
self.aws[key].checked_items += summary[key]["checked_items"]
self.aws[key].flagged_items += summary[key]["flagged_items"]
self.aws[key].resources_count += summary[key]["resources_count"]
self.aws["total"].checked_items += summary[key]["checked_items"]
self.aws["total"].flagged_items += summary[key]["flagged_items"]
self.aws["total"].resources_count += summary[key]["resources_count"]
self.total.checked_items += summary[key]["checked_items"]
self.total.flagged_items += summary[key]["flagged_items"]
self.total.resources_count += summary[key]["resources_count"]
if cloud == CloudProvider.AZURE:
for key in self.azure.keys():
if key != "total":
self.azure[key].checked_items += summary[key]["checked_items"]
self.azure[key].flagged_items += summary[key]["flagged_items"]
self.azure[key].resources_count += summary[key]["resources_count"]
self.azure["total"].checked_items += summary[key]["checked_items"]
self.azure["total"].flagged_items += summary[key]["flagged_items"]
self.azure["total"].resources_count += summary[key][
"resources_count"
]
self.total.checked_items += summary[key]["checked_items"]
self.total.flagged_items += summary[key]["flagged_items"]
self.total.resources_count += summary[key]["resources_count"]
if cloud == CloudProvider.GCP:
for key in self.gcp.keys():
if key != "total":
self.gcp[key].checked_items += summary[key]["checked_items"]
self.gcp[key].flagged_items += summary[key]["flagged_items"]
self.gcp[key].resources_count += summary[key]["resources_count"]
self.gcp["total"].checked_items += summary[key]["checked_items"]
self.gcp["total"].flagged_items += summary[key]["flagged_items"]
self.gcp["total"].resources_count += summary[key]["resources_count"]
self.total.checked_items += summary[key]["checked_items"]
self.total.flagged_items += summary[key]["flagged_items"]
self.total.resources_count += summary[key]["resources_count"]
Once the final report has been generated, it needs to be stored along with the static JavaScript, CSS, and HTML files generated by ScoutSuite. This allows us to view the raw scan results and fetch the aggregated report from the same location. I've used an AWS S3 bucket for this, but any storage solution would work – S3 just has the added benefit of being able to host the HTML files at no additional cost. Here's a look at the file upload logic:
def upload_html(html_files: List[str]) -> None:
"""
Upload raw html files
"""
# Loop through html files
for file_path in html_files:
key = f"scoutsuite-raw/{file_path.split('/')[-1]}"
# Open in binary mode so boto3 can stream efficiently
with open(file_path, "rb") as file_obj:
s3.put_object(
Bucket=Config.S3_BUCKET,
Key=key,
Body=file_obj,
ContentType="text/html",
)
Logger.info(f"Uploaded {file_path} to s3://{Config.S3_BUCKET}/{key}")
# Upload index file
s3.put_object(
Bucket=Config.S3_BUCKET,
Key="index.html",
Body=generate_index(),
ContentType="text/html",
)
Logger.info(f"Uploaded index.html to s3://{Config.S3_BUCKET}/index.html")
Done! Now we can kick off our cloud scans, combine all the data into a report, and upload the raw results – all in one process. In the next part, I'll go over how we automated this workflow so it can all be done without lifting a finger.

Part 2 - Scheduled Scans & Pipeline Integration
To automate the process from Part 1, we'll take advantage of Bitbucket Pipelines to handle scheduling, OIDC, and secret management. You could easily use GitHub Actions for this as well, but this time we chose Bitbucket. Here's how it works:
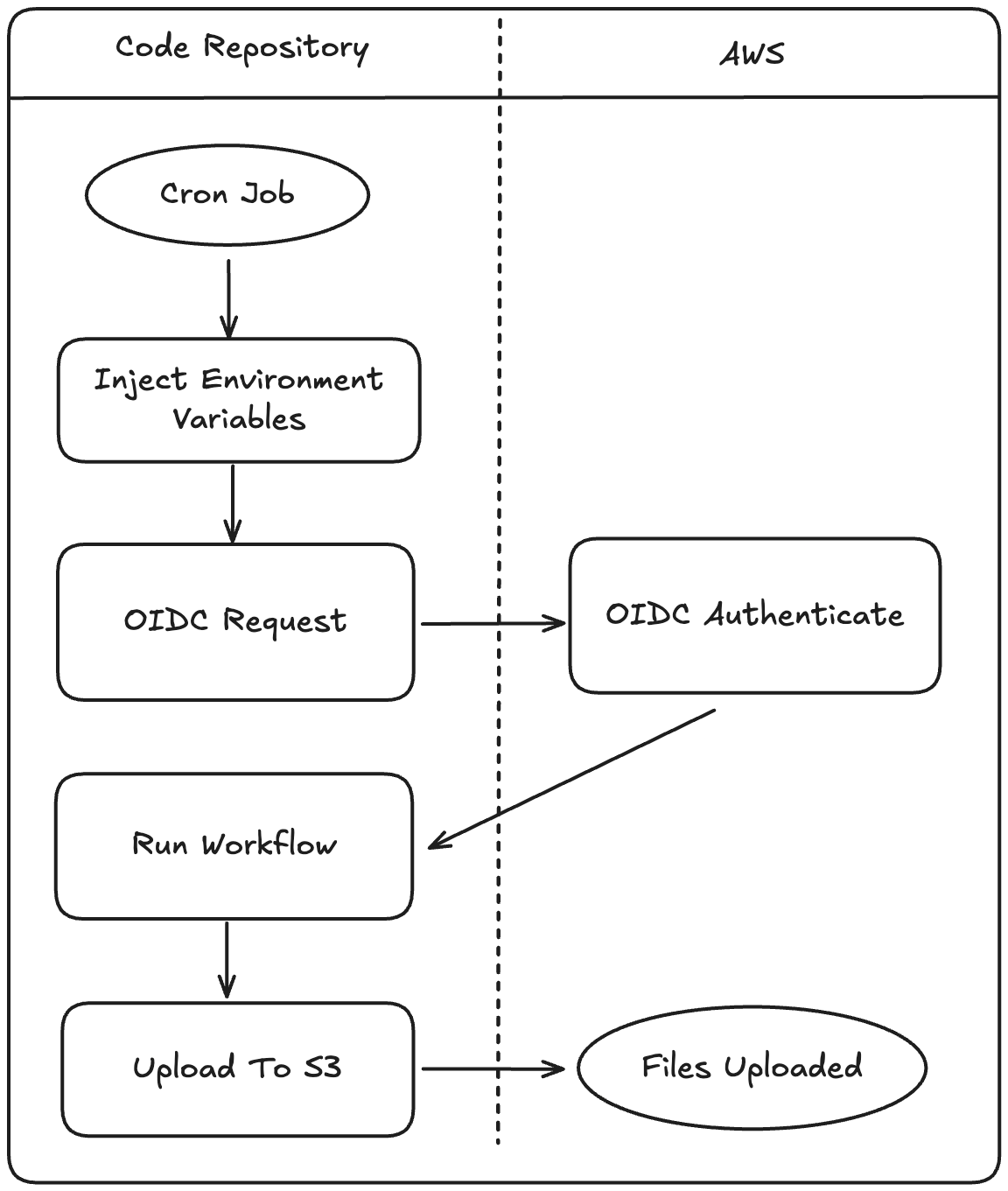
The workflow itself is fairly simple – we'll configure some variables, install the Python dependencies, and kick off the scanning process. Here's a look at the YAML for all this:
image: python:3.11
pipelines:
schedules:
- cron: '0 2 * * 1' # Mondays @ 02:00 UTC
branch: main # <— the branch you want to run this on
step:
name: Weekly Scan
oidc: true
caches:
- pip
script:
- echo "$BITBUCKET_STEP_OIDC_TOKEN" > oidc_token
- export AWS_WEB_IDENTITY_TOKEN_FILE=$(pwd)/oidc_token
- export AWS_ROLE_ARN=$AWS_OIDC_ROLE_ARN
- export AWS_REGION=us-west-2
- pip install -r requirements.txt
- python main.py
OIDC
We're using OIDC to connect to the AWS account that will store our static files in S3. To set this up, we created a role for the pipeline to assume and added an identity provider in AWS IAM. The official documentation covers this in more detail than I need to include here.
Static Credentials
Credentials for each cloud account are stored in the repository's secrets. While we could use an external solution like AWS Secrets Manager, I prefer to keep this project self-contained whenever possible. Ideally, we would use OIDC instead of static credentials to authenticate with all the cloud accounts. However, both GitHub Actions and Bitbucket Pipelines perform the built-in OIDC exchange only once per step. This means that if you need to access multiple accounts within a single step, you must manually assume each additional role or service account and re-export the resulting environment variables for each one.
Although this approach offers better security, it quickly becomes cumbersome in a CI/CD pipeline, so I won't worry about it for now. Maybe I'll come up with a better workaround in the future.

The good news is that we now have automated weekly scans and reports being uploaded and served. The only thing left is to build a dashboard to visualize it all.
Part 3 - Data Visualization & Conclusion
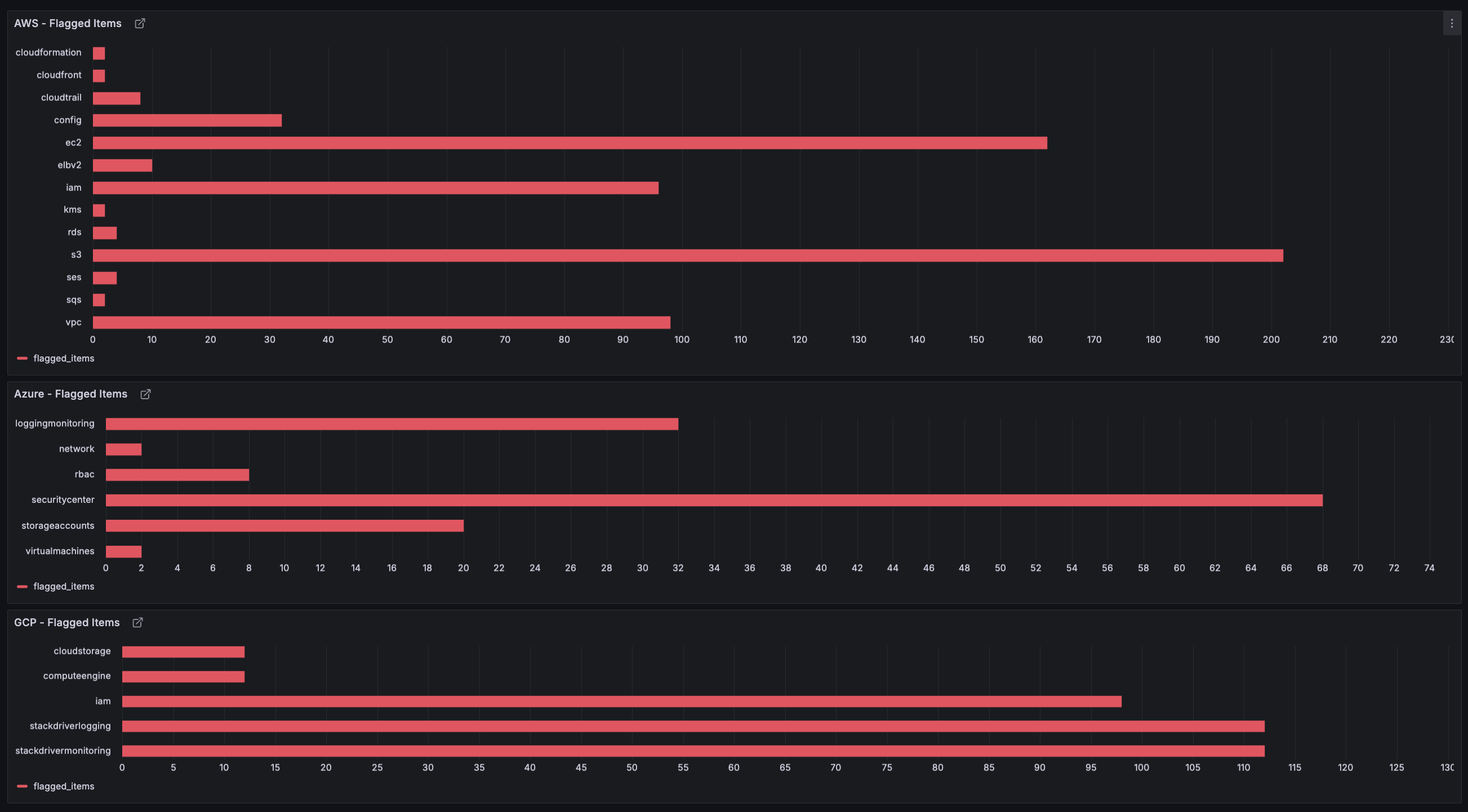
To easily visualize our data without building an entire dashboard from scratch, we're using Grafana. With Grafana, we can set the S3 bucket that stores our reports as the data source and use that to create panels. I've started by creating panels that show the number of flagged resources across all our cloud accounts.
To quickly set up Grafana, we just need to pull the Docker image and run it as a container. I'm running it in detached mode using the -d flag so that it stays running in the background.
docker pull grafana/grafana
docker run -d -p 3000:3000 --name=grafana grafana/grafana
Infinity Plugin
Next, we need to set up our data source. To parse JSON data and fetch it from S3, we use the "Infinity" plugin, which can be installed from Grafana's plugins page. To add our report data as a data source, go to Connections > Data sources > Add new data source and select Infinity.
Here, we can configure any required authentication and point Grafana to our bucket URL, which should look like this:
https://.s3..amazonaws.com/.
It's important to note that static website hosting must be enabled on our S3 bucket for this to work.
To create the bar graphs shown above, first create a dashboard and add a visualization. Then enter the URL and path of the latest report, which I'm storing at /scoutsuite-reports/report_latest.json in our bucket. Finally, parse the data and add transformations as needed to fit our requirements.
What's Next
Adding ScoutSuite alone is already a major improvement to our cloud security and observability, but we can go even further. Custom rules for ScoutSuite can help tailor scans to our specific needs. The report data can be adjusted, and more panels can be set up in Grafana to display additional helpful metrics. To cover blind spots left by ScoutSuite, we could also make use of additional open-source tools like the following:
-
KubeHunter – Performs in-depth auditing of Kubernetes clusters, which is missing from ScoutSuite.
-
tfsec – Scans our Terraform code to help prevent security issues before deployment.
-
Trivy – Scans container registries and inspects images for vulnerable or outdated libraries.
-
OWASP ZAP – Probes our running web applications and APIs for security vulnerabilities.
That's it! Hopefully, some of this has been informative. Thanks for reading :D